
VentureBeat presents: AI Unleashed – An exclusive executive event for enterprise data leaders. Hear from top industry leaders on Nov 15. Reserve your free pass
Fine-tuning large language models (LLM) has become an important tool for businesses seeking to tailor AI capabilities to niche tasks and personalized user experiences. But fine-tuning usually comes with steep computational and financial overhead, keeping its use limited for enterprises with limited resources.
To solve these challenges, researchers have created algorithms and techniques that cut the cost of fine-tuning LLMs and running fine-tuned models. The latest of these techniques is S-LoRA, a collaborative effort between researchers at Stanford University and University of California-Berkeley (UC Berkeley).
S-LoRA dramatically reduces the costs associated with deploying fine-tuned LLMs, which enables companies to run hundreds or even thousands of models on a single graphics processing unit (GPU). This can help unlock many new LLM applications that would previously be too costly or require huge investments in compute resources.
Low-rank adaptation
The classic approach to fine-tuning LLMs involves retraining a pre-trained model with new examples tailored to a specific downstream task and adjusting all of the model’s parameters. Given that LLMs typically have billions of parameters, this method demands substantial computational resources.
VB Event
AI Unleashed
Don’t miss out on AI Unleashed on November 15! This virtual event will showcase exclusive insights and best practices from data leaders including Albertsons, Intuit, and more.
Parameter-efficient fine-tuning (PEFT) techniques circumvent these costs by avoiding adjusting all of the weights during fine-tuning. A notable PEFT method is low-rank adaptation (LoRA), a technique developed by Microsoft, which identifies a minimal subset of parameters within the foundational LLM that are adequate for fine-tuning to the new task.
Remarkably, LoRA can reduce the number of trainable parameters by several orders of magnitude while maintaining accuracy levels on par with those achieved through full-parameter fine-tuning. This considerably diminishes the memory and computation required to customize the model.

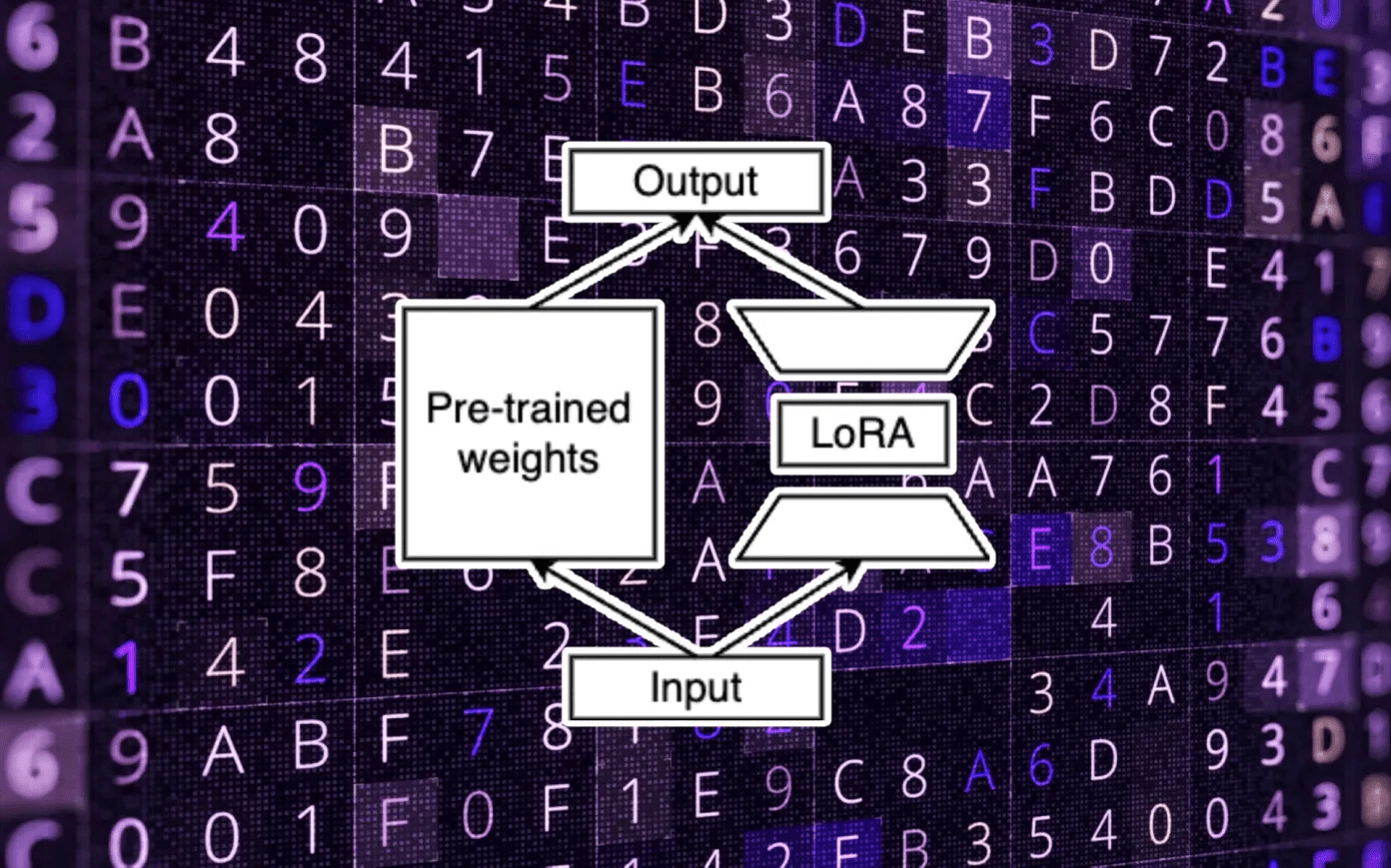
The efficiency and effectiveness of LoRA have led to its widespread adoption within the AI community. Numerous LoRA adapters have been crafted for pre-trained LLMs and diffusion models.
You can merge the LoRA weights with the base LLM after fine-tuning. However, an alternative practice involves maintaining the LoRA weights as separate components that are plugged into the main model during inference. This modular approach allows for companies to maintain multiple LoRA adapters, each representing a fine-tuned model variant, while collectively occupying only a fraction of the main model’s memory footprint.
The potential applications of this method are vast, ranging from content creation to customer service, making it possible for businesses to provide bespoke LLM-driven services without incurring prohibitive costs. For instance, a blogging platform could leverage this technique to offer fine-tuned LLMs that can create content with each author’s writing style at minimal expense.
What S-LoRA offers
While deploying multiple LoRA models atop a single full-parameter LLM is an enticing concept, it introduces several technical challenges in practice. A primary concern is memory management; GPUs have finite memory, and only a select number of adapters can be loaded alongside the base model at any given time. This necessitates a highly efficient memory management system to ensure smooth operation.
Another hurdle is the batching process used by LLM servers to enhance throughput by handling multiple requests concurrently. The varying sizes of LoRA adapters and their separate computation from the base model introduce complexity, potentially leading to memory and computational bottlenecks that impede the inference speed.
Moreover, the intricacies multiply with larger LLMs that require multi-GPU parallel processing. The integration of additional weights and computations from LoRA adapters complicates the parallel processing framework, demanding innovative solutions to maintain efficiency.
S-LoRA uses dynamic memory management to swap LoRA adapters between main memory and GPU
The new S-LoRA technique solves these challenges through a framework designed to serve multiple LoRA models. S-LoRA has a dynamic memory management system that loads LoRA weights into the main memory and automatically transfers them between GPU and RAM memory as it receives and batches requests.
The system also introduces a “Unified Paging” mechanism that seamlessly handles query model caches and adapter weights. This innovation allows the server to process hundreds or even thousands of batched queries without causing memory fragmentation issues that can increase response times.
S-LoRA incorporates a cutting-edge “tensor parallelism” system tailored to keep LoRA adapters compatible with large transformer models that run on multiple GPUs.
Together, these advancements enable S-LoRA to serve many LoRA adapters on a single GPU or across several GPUs.
Serving thousands of LLMs
The researchers evaluated S-LoRA by serving several variants of the open-source Llama model from Meta across different GPU setups. The results showed that S-LoRA could maintain throughput and memory efficiency at scale.
Benchmarking against the leading parameter-efficient fine-tuning library, Hugging Face PEFT, S-LoRA showcased a remarkable performance boost, enhancing throughput by up to 30-fold. Compared to vLLM, a high-throughput serving system with basic LoRA support, S-LoRA not only quadrupled throughput but also expanded the number of adapters that could be served in parallel by several orders of magnitude.
One of the most notable achievements of S-LoRA is its ability to simultaneously serve 2,000 adapters while incurring a negligible increase in computational overhead for additional LoRA processing.
“The S-LoRA is mostly motivated by personalized LLMs,” Ying Sheng, a PhD student at Stanford and co-author of the paper, told VentureBeat. “A service provider may want to serve users with the same base model but different adapters for each. The adapters could be tuned with the users’ history data for example.”
S-LoRA’s versatility extends to its compatibility with in-context learning. It allows a user to be served with a personalized adapter while enhancing the LLM’s response by adding recent data as context.
“This can be more effective and more efficient than pure in-context prompting,” Sheng added. “LoRA has increasing adaptation in industries because it is cheap. Or even for one user, they can hold many variants but with the cost of just like holding one model.”
The S-LoRA code is now accessible on GitHub. The researchers plan to integrate it into popular LLM-serving frameworks to enable companies to readily incorporate S-LoRA into their applications.
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Discover our Briefings.





